

日本語の言語特性に起因する誤読のメカニズムと多角的リスク
企業研修、デジタル教材、顧客向けFAQなどの領域において、テキストや既存スライド資料から自動で動画を量産する技術が急速に普及している1。しかし、日本語の複雑な言語構造は、自動生成プロセスにおいて「音声合成の誤読」という深刻な課題を突きつけている4。日本語は、漢字・ひらがな・カタカナ・ローマ字が複雑に入り交じる極めて珍しい表記体系を持つ6。このため、テキストを音素に変換するG2P(Grapheme-to-Phoneme)処理において、文脈判断に基づく同音異義語や同形異音語の判別エラーを完全に排除することは本質的に困難である7。
形態素解析と音素変換の限界
日本語のG2Pタスクは、書記素列 から最も尤もらしい音素列
を推定する以下の確率モデルとして定式化される7。
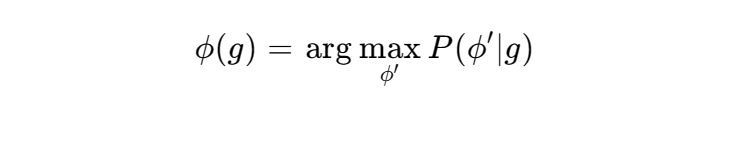
漢字かな混じりデータを用いた学習では、同音異義語の判別が認識エラーとして混入しやすいため、高精度な音素変換モデルの構築にはカナ表記をベースにした純粋な音素データセットによる学習が必要とされている7。さらに、日本語の音素構造は、後続の子音や母音の性質に強く影響される。例えば、撥音「ん」の音素 [N] は、後続の音に応じて両唇鼻音 [m]、歯茎鼻音 [n]、軟口蓋鼻音 [ŋ]、あるいは uvular [ɴ] などへと複雑に鼻音同化(同化作用)を起こす9。また、母音の無声化(例えば「す」 [s ɯ] が [ɕ ɨ] に変化する現象など)や、口蓋化、有声破擦音への移行といった音素レベルのミクロな動的変化が絶えず発生する9。これらに加え、日本語は平板型、頭高型、中高型、尾高型に代表される「高低アクセント(ピッチパターン)」によって語意を峻別する言語であるため、これらの制御を誤ると聴者に致命的な違和感を与えるか、全く異なる意味として誤認されるリスクが生じる10。文脈上、読みが定まらない形態素(同形異音語)に対しては、文頭からと文末からの双方向で形態素の照合・判定を行う双方向スキャンアルゴリズムなどを併用し、局所的な曖昧さを文脈から解消するアプローチが不可欠となっている8。
動画生成特有のハルシネーションと社会的・法的リスク
情報の正確性が担保されないまま動画が生成されると、単に音声が聞き取りづらいという問題に留まらず、多様な技術的・社会的リスクが顕在化する5。動画特有のハルシネーションとして、物理法則を完全に無視したアバターや物体の挙動、画面上のテロップ字幕における意味不明な文字列の出力、あるいはフレーム間の不自然な連続性の崩れ(ちらつきや崩壊)が挙げられる11。さらに、LLMが架空の研究論文や存在しない事例、出典のない偽データをさも真実であるかのように出力する現象も報告されている12。
このような不正確なコンテンツが、医療、法律、金融、公共制度といった「誤読コストが極めて高い専門領域(YMYL:Your Money or Your Life)」で配信された場合、ユーザーの意思決定を誤らせるだけでなく、配信主体の社会的信用を壊滅的に失墜させる要因となる12。顧客獲得や信頼構築の観点からも、Googleの検索アルゴリズム変更(AI Overviewの導入など)に伴い、Webサイトのオーガニッククリック率(CTR)が平均34.5%(2025年4月時点)から58%(2025年12月時点)へと大幅に低下する中で、検索トラフィックに頼らない「直接的な動画による信頼獲得」の重要性が増している2。しかし、情報の正確性を曖昧にしたまま公開すると、初期解約率(チャーンレート)の増加やブランド毀損に直結する1。
また、情報発信における正確性を証明するための「ラベル表示」の影響を分析した総務省の実証データによれば、弱い表現のラベル(ラベル型・弱)は、視聴者が「どちらとも言えない」という不確実な判断を選択する確率を2.18パーセント増加させることが確認されている15。これは、わずかな品質の妥協や曖昧なファクトチェックが、視聴者の信頼感を著しく減退させる実証的証拠である15。
さらに、ビジネス利用における法的・倫理的リスクも軽視できない11。実在人物(著名人や自社社員を含む)の顔や声をAIで合成・クローン化することは、肖像権、パブリシティ権、名誉権の侵害に直結する危険があり、なりすましやディープフェイクとしての社会的問題も内包している11。そのため、本人の書面同意を得た上での「AI生成」の明示やウォーターマーク(透かし)技術の埋め込み、社内ガイドラインの策定が不可欠となる11。また、著作物を不適切に学習データとして用いた生成モデルが、既存の作品と酷似した動画を出力した場合には、著作権侵害の法的トラブルに巻き込まれる可能性が極めて高いため、情報のソース管理と徹底した検証が実務上強く求められる13。
主要プラットフォームの誤読防止技術と機能比較
このような課題に対し、市場に存在する主要な動画生成および音声合成システムは、独自のアルゴリズムや制御インターフェースを導入することで、発音精度の大幅な向上を図っている。これらは単純なテキスト変換エンジンに留まらず、辞書共有、アクセントのビジュアル編集、LLM連携による高度な文脈推定など、多様なアプローチを提示している2。
以下の表は、誤読率を極限まで低減させるために有効な主要プラットフォームの技術的特徴、インターフェース、共有機能、および実用上の検証データを比較したものである。
| プラットフォーム | 誤読防止コア技術と特徴 | インターフェースと制御能力 | 組織内共有・協業対応 | 主要用途と実績・実証精度 |
| NoLang | 難読な歴史用語、理数系の専門用語、独自の組織内造語を網羅する専用「辞書機能」を搭載2。PDF、PPTX、WebサイトURL、動画、音声を瞬時に統合変換可能1。 | テキストからアバター動画および編集可能なPPTXスライドを自動で同期生成2。 | 法人プランでの組織内共有辞書設定。複数メンバー間での教材品質の統一化2。 | eラーニング教材、製品FAQ、マニュアル動画。初期解約率(チャーンレート)の低減に貢献1。 |
| VOICEPEAK | ユーザー登録単語を最優先する内蔵辞書20。最新の深層学習モデルによる高品質な日本語TTS16。オフライン動作による機密性確保16。 | イントネーション調整画面。音素ピッチ(●)のビジュアル描画・直接ドラッグによるピッチ修正20。 | 個別エクスポート。ユーザー定義辞書(CSV等)のインポートによる手動共有。 | 保険約款等の汎用性検証において、読み、アクセント、間で「85%以上」の正確性を実証22。 |
| Vyond | 発音編集機能(Text to Speechの発音編集)19。Google Geminiとの統合による高品質音声(Ultra High Quality Voices)の生成19。 | ひらがな・カタカナを入力して直接発音を上書き指定。一部高品質音声での速度・イントネーション微細調整19。 | チーム・Enterpriseプラン内での共通アセット、ライブラリ、およびキャラクター設計の共有。 | 企業内研修アニメーション、サービス紹介動画、セキュリティ啓発動画。 |
| Vrew / VOICEVOX | Vrew独自の「単語辞書」機能(ベータ)23。VOICEVOXのユーザー辞書(voicevox_user_dict.csv)への直接書き込み対応24。 | ひらがな・カタカナによる表記の上書き23。検索と置換(Ctrl+H)による複数箇所の一括誤読修正26。 | 基本的にローカルPCでの運用(辞書ファイルの直接受け渡しによる共有は可能)。 | SNS投稿動画、講義資料の副音声付与、プロトタイプ解説動画16。 |
| NotebookLM (Audio Overview) | Google Geminiベースのダイアログ生成。生成パラメーター「Customize」欄での事前読み仮名プロンプト指定(最大500文字)27。 | 元ドキュメント(HTML・PDF等)側への<ruby>タグや丸括弧カナ表記の埋め込みによる音声読み優先制御27。 | 共有ノートブック上での設定共有(参加メンバー全員が同じソースとプロンプトにアクセス可能)。 | 技術資料・仕様書・学術論文の対話型ポッドキャスト化、音声要約27。 |
| AITalk | 新DNN音声合成方式と独自の日本語解析技術28。感情表現(大人から子供、方言対応)28。自分の声を再現する「あなたの声」機能29。 | 単語および固有名詞のユーザー辞書登録、テキスト内へのルビ直接記述による読み制御29。 | サーバーSDKやWebAPIを介した全社的な音声エンジン・用語データベースの統一。 | 各種音声放送インフラ、自社アバターへの音声供給。AI-OCR(認識精度99.6%)と連携した帳票自動化とのシナジー13。 |
上記のデータが示すように、プラットフォームごとに適したドメインは異なる。例えば、生命保険会社の約款のように非常に厳格な日本語解析が求められる検証において、最新の追加学習モデルは「読み」「アクセント」「間」の基本三要素で85%以上のネイティブ水準の正確性を実証している22。また、業務効率化の文脈では、認識精度99.6%を誇るAI-OCR技術等と連動させることで、紙書類からテキストデータを抽出し、それをAITalkやVOICEPEAKなどのエンジンに渡すことで、手入力作業をほぼゼロにしながら解説動画や音声解説を自動量産するパイプラインも構築されている13。
誤読率0%を達成するための3段階プロダクション・パイプライン
解説型動画において、聴覚的および視覚的なエラーを極限まで排除し「誤読率0%」を追求するためには、単一ツールの利用に依存せず、上流の原稿作成から下流の人間による検証に至る「3段階プロダクション・パイプライン」を構築・運用することが求められる13。
第一段階:言語的前処理とスクリプトの平準化
すべての音声・動画生成の成否は、インプットとなるスクリプト(原稿)の品質によって決定される20。音声合成エンジンが解析しやすいよう、あらかじめ言語学的に最適化された原稿作成ルールを順守する必要がある20。
第一に、同形異音語の誤解釈を防ぐため「漢字を開く(ひらがな化する)」という処理を徹底する20。「出来る」を「できる」、「言う」を「いう」と表記するだけで、形態素解析時の無用な読み分けエラーをシステム的に回避できる20。また、文末表現(終助詞)のトーンを統一し、「です・ます」調の中に「だ・である」調が混在しないようスクリプトの整合性を保つことも、エンジンの予測精度維持に不可欠である20。
第二に、算用数字や記号の処理基準を設ける。音声合成エンジンに算用数字を直接入力する(例:「3本」「5冊」)と、文脈によって正しく助数詞が読まれないケースが生じる6。そのため、原稿段階で「三本(さんぼん)」「五冊(ごさつ)」のように、漢数字による明示的な表記、あるいは読み仮名を直接定義する6。通貨記号についても「¥1,500」を「千五百円」と表記するか、あるいは自動読み上げに頼る場合は「円」単位が正しく解釈されるかを確認する6。日付(2024年3月15日)や時刻(14時30分)などの順序や単位表記も、漢字による日付記号を厳格に付与することで誤読リスクを大幅に低下させられる6。
第三に、業界専門用語や組織内独自のアルファベット略語(例:「KPI」「DX」など)については、原稿上でインライン・ルビ記法(例:DX《ディーエックス》)を使用し、読み間違いの可能性を根底から排除する20。VOICEVOXの連携機能を利用する場合、以下のようなフォーマットで記述されたユーザー辞書用CSVファイルを事前生成し、システムにロードするアプローチが極めて有効である24。
鬱蒼,うっそう,0,1
このように「表記、読み仮名、アクセント区切り位置」を構造化してシステムに渡すことで、未知の専門用語であっても音声エンジンは完璧なイントネーションで発話を開始することが可能となる24。
第二段階:AI音声合成の精密制御パラメーター
自動生成フェーズにおいては、エンジンの再生パラメーターを人間の認知的理解に最も適した値(黄金比)に固定する20。音声が単調(棒読み)であると、受講者や視聴者は退屈さを感じ、注意力を失ってしまう20。これを防ぎ、生命感のあるナレーションを実現するために、以下の制御パラメーターをシステム側でプリセット化する。
- 話速(ナレーション速度)の最適化
現代の視聴者、特にタイパ(タイムパフォーマンス)を重視する世代に向けたeラーニング教材やFAQ動画では、1分間あたり350文字以上の速度が求められる傾向にある20。そのため、話速スライダーを「105%から115%」に設定し、標準よりもわずかに速く歯切れの良いリズムを形成する20。 - 抑揚およびピッチの強調
人間の感情の揺らぎや文脈上の強調を再現するため、抑揚パラメーターを「+10%から+15%」に設定し、文末のピッチ(トーン)をわずかに下げるようピッチ調整を施す20。これにより、ナレーション全体に落ち着きと教材としての高い安定感が備わる20。 - 感情パラメーターの微量付与
VOICEPEAKなどの感情制御に対応したエンジンを使用する場合、感情パラメーターの「喜び(Happiness/Joy)」を「10%から20%」の間で微量に注入する20。これにより、機械的な冷たさが一掃され、受講者が親しみやすさを抱くような温かみのある音声へと変化する20。 - 「間(ポーズ)」のミリ秒単位の設計
ナレーションの分かりやすさを決定づける最も重要な要素は、単語や文の区切りにおける「ポーズ(間)」の長さである20。一般的なデフォルト設定に依存せず、文末の句点(。)や改行部分におけるポーズ時間を「1.0秒」に延長する20。受講者が提示された情報を頭の中で処理するための認知的余白が生まれ、理解度が劇的に向上する20。逆に、読点(、)におけるポーズはデフォルトのままとするか、テンポを損なわないよう「0%」に極小化する箇所を意図的に織り交ぜることで、メリハリのある自然な発話リズムを作り出す20。
第三段階:人間介在型品質保証と持続的フィードバックループ
テクノロジーの進歩によってAI生成の精度が極限まで高まったとしても、確率的な振る舞いに由来する微細なエラー(ハルシネーションや不自然な音素の結合歪みなど)を「自動処理だけで完全に0%」にすることは原理的に不可能である11。したがって、最終的な配信前に「人間が介在する品質保証(Human-in-the-Loop)」のレビュー工程をワークフローの最後に必ず構築する11。
具体的には、生成された動画アセットに対し、専門の校正スタッフが全編を通しで視聴・聴取するスクリーニングを実施する11。この際、教科書や製品仕様書といった「正解ソース」と照らし合わせ、AIが出力したスクリプトや発音が客観的事実から逸脱していないかをトリプルチェックする13。
もし特定の単語やフレーズで誤読が発生していた場合、Vrewの「検索と置換(Ctrl+H)」などの一括置換ツールを利用して、字幕と内部音声をピンポイントで修正する23。さらに、その場での局所的な修正に留めず、修正された「表記と正しい読み」を直ちにシステム全体の「組織内共有辞書」にフィードバックとして登録(インクリメンタル学習)する2。
このフィードバックサイクルを継続的に回すことにより、同じ専門用語に対する誤読の再発は次回の生成から「完全に0%」となり、アセット作成を重ねるほどにワークフロー全体の自動化率が向上し、人間のレビュー負荷自体が低減されていく自律的な品質改善ループが完成する2。
また、この最終検証フェーズにおいては、前述の法的・セキュリティ的観点から、個人情報や企業秘密がモデルの外部学習ソースに流出していないかのチェックや5、生成されたキャラクターやアバター、音声にディープフェイクや著作権侵害の兆候(既存の作品との過度な類似)がないかどうかのリーガルリスク検証も同時に実施される11。
ゼロ誤読がもたらす組織的ベネフィットと認知的影響
解説型動画において誤読率を0%に極限まで近づけるアプローチは、単なるテキスト音声化の精度向上という局所的な成果に留まらず、学習者の認知的受容プロセスの変革や、企業の持続的なビジネス成果の創出に対して広範なインパクトをもたらす。
認知科学的観点から言えば、人間の脳は不自然なイントネーションや誤読に直面した瞬間、そのエラーを認知的に補正しようとする無意識の翻訳作業にワーキングメモリを強制的に配分してしまう。特に、難解な技術マニュアルや数式、あるいは法律約款などを解説する動画において、誤読による不要なノイズは学習者の認知負荷を最大化させ、コンテンツの主たるテーマである「解説内容自体の理解」を著しく阻害する原因となる20。
誤読を完全に駆逐したナレーションと、ミリ秒単位で完全に同期された字幕およびスライド提示は、学習者の脳をノイズ処理から解放し、提示された概念の抽象的思考や応用理解にすべての認知リソースを集中させることを可能にする3。
また、実務的なビジネス展開における生産性と付加価値の観点でも、この統合アプローチは劇的な効果を発揮する。
- 制作コストと再収録の手戻り時間の極小化
従来のナレーターを起用したスタジオ収録では、原稿の一部変更や誤読の発覚に伴い、数日以上の調整期間と高額な再収録コストが都度発生していた5。本パイプラインを採用することで、テキストの修正から再生成まで数分以内で完結するため、情報の更新頻度が極めて高い製品FAQや、法改正が頻発する規約解説動画などの運用コストを最大で数十分の一にまで圧縮できる1。 - 顧客満足度の向上と顧客生涯価値(LTV)の最大化
正確で直感的に理解できる動画マニュアルの展開は、ユーザーが製品の初期設定や導入プロセスで直面する「つまずき」を効果的に解消する1。これにより、製品購入直後の解約率(チャーンレート)を優位に低減させ、顧客エンゲージメントの向上を通じてLTVの最大化をもたらす1。 - アバター連携による保護者・顧客からの信頼醸成
教育サービスや学習塾などの対面信頼が重視されるドメインにおいては、実在する名物講師や教室スタッフを忠実にデジタル再現した「リアルAIアバター」を活用することで、講師不足の解消と指導品質の均一化を両立できる2。正確な発音で語りかける高精度アバター動画は、長文の「合格体験記」や「講師紹介」を読まない直感的な保護者に対しても熱量と安心感を短時間で伝達し、Webサイト訪問者の直帰を抑え、問い合わせ率や入塾入会へのコンバージョンレート(CVR)を大きく向上させる2。 - グローバル展開における一貫性の保持
複数の国や言語に対して同時に仕様変更情報を届ける場合でも、18言語に対応した動的言語変換機能と組織内共有辞書の組み合わせを活用すれば、多国籍にわたるFAQやマニュアルの品質、ブランドイメージ、および専門用語の正確性を瞬時に均一化し、ローカライズに伴うタイムラグを消滅させることが可能となる1。
このように、誤読率を限りなくゼロに近づけるための技術的プラクティスとワークフローの構築は、不確実性の高まる現代のデジタル情報社会において、配信側と視聴者側の双方が享受する認知的・商業的ベネフィットを最大化するための極めて不可避かつ強力な戦略的インフラとなる2。
引用文献
- 動画生成AI「NoLang」、18言語対応&動画の言語変換機能を追加し、テキスト/資料の入力だけで海外向けFAQ・マニュアル動画を即座に生成。海外顧客向けのカスタマーサポートを自動化・効率化へ | 株式会社Mavericksのプレスリリース – PR TIMES, https://prtimes.jp/main/html/rd/p/000000065.000129953.html
- 教育業界向けに本格展開。授業の教材や合格体験記などの既存資産を瞬時に動画化し、指導効率化や集客強化を実現:東京新聞 × PR TIMES, https://adv.tokyo-np.co.jp/prtimes/article105133/
- 動画生成AI「NoLang」、教育業界向けに本格展開。授業の教材や合格体験記などの既存資産を瞬時に動画化し、指導効率化や集客強化を実現 | 株式会社Mavericksのプレスリリース – PR TIMES, https://prtimes.jp/main/html/rd/p/000000073.000129953.html
- AI音声読み上げサービスとは?仕組み・活用事例・導入のメリットとデメリットを解説 | DXPOカレッジ, https://dxpo.jp/college/front/advertisement/ai-speaker.html
- 音声生成AIとは?日本語対応の高精度ツール徹底比較, https://www.leadplus.co.jp/blog/what-is-voice-generation-ai
- 日本語テキスト読み上げ – AI音声合成 – SpeechGen.io, https://speechgen.io/ja/tts-japanese/
- 日本語におけるG2Pによる統計的学習を用いた 話し言葉に頑健な発音辞書の自動構築 – 情報処理学会電子図書館, https://ipsj.ixsq.nii.ac.jp/record/182876/files/IPSJ-SLP17117011.pdf
- 音声合成システムのための同形異音語の読み分け – 豊田中央研究所, https://www.tytlabs.co.jp/en/japanese/review/rev351pdf/351_067umemura.pdf
- TTS における日本語 G2P(Grapheme-to-Phoneme) – Zenn, https://zenn.dev/nnn112358/scraps/2fa2b762aadd1b
- 日本語テキスト読み上げ – 高低アクセントと敬語対応のAI音声 | AnySpeech, https://anyspeech.io/ja/japanese-text-to-speech
- AI動画生成とは|業務での使い方と著作権・ディープフェイクのリスク対応【ガイドライン準拠】, https://www.onamae.com/business/article/280445/
- AIにおける「ハルシネーション」とは?原因と対策をわかりやすく解説 – アルサーガパートナーズ, https://www.arsaga.jp/blog/dxcolumn-what-is-hallucination/
- AIコラム:生成AIが抱える問題点を徹底解説! | 富士フイルムビジネスイノベーション – Fujifilm, https://www.fujifilm.com/fb/ja/solutions/columns/ai-11636
- AI Overviewsとは?SEOへの影響と対策を2026年最新データで解説 – EmmaTools, https://emma.tools/magazine/ai-overview/
- 生成AI時代における偽誤情報流通と 認知特性の解明に関する研究・調査 成果報告書概要版, https://www.soumu.go.jp/main_content/001068769.pdf
- 音声生成AIとは?仕組みと、おすすめアプリ10選, https://www.icd.co.jp/solutions/voice-ai/
- 生成AIの利用方法 – 東京経済大学, https://www.tku.ac.jp/iss/guide/classroom/ai/
- 動画生成AI「NoLang」に辞書機能を追加 固有名詞や専門用語の, https://no-lang.com/news/nolang-dictionary-feature-2025-11/
- テキストから音声を作る 音声合成 Text to Speech – VYOND, https://animedemo.com/trial/text-to-speech2025/
- ナレーションの「手戻り地獄」を終わらせる!eラーニング制作者必見:VOICEPEAKで高品質ナレーションを作成する方法 – Qualif(クオリフ), https://qualif.jp/lab/voicepeak/
- 全体の読み上げを調整 – VOICEPEAK 機能マニュアル, https://www.ah-soft.com/voice/manual/1.1/03_useage.html
- DNP、橋/箸を正確に発音する合成音声。文脈から誤読も防ぐ – Impress Watch, https://www.watch.impress.co.jp/docs/news/1331556.html
- AI音声の発音や読み方を修正したいです。 – Vrewコミュニティ, https://vrewjp.imweb.me/FAQ/?bmode=view&idx=16066418
- 【VOICEBOX編007】読み間違いが多い固有名詞や難読語も、”カスタム辞書”を使えば自由に調整OK! – note, https://note.com/tsuki_kotoba/n/n66f7c639f9d3
- 【VOICEBOX編008】VOICEVOXで広がる!カスタム辞書のススメ – note, https://note.com/tsuki_kotoba/n/n0622bcf523ec
- AI自動字幕の入れ方|Vrewで作業時間を90%短縮する方法【2026年版】 – オムニウェブ, https://omniweb.jp/m138/
- NotebookLMが読み間違えて音声Potcastが残念になるのを防ぐ方法。:覚書, https://blog.bnd.jp/?p=12464
- 音声合成 AITalk® とは? – 株式会社エーアイ, https://www.ai-j.jp/about/
- 自分の声を再現できるAI音声合成ソフト5選!選び方から活用例まで詳しく解説 – 株式会社エーアイ, https://www.ai-j.jp/blog/ai/my-voice/
- 【検証】「AIで動画生成を全自動化!」の甘い罠。ゼロからショート動画を作ってみてわかった残酷な(?)真実 – note, https://note.com/ainohumi/n/n0fd11cb851bf
- 生成AI(ジェネレーティブAI)とは?種類や活用のメリット、活用事例をご紹介 – 日立ソリューションズ, https://www.hitachi-solutions.co.jp/digitalmarketing/sp/column/ai_vol04/
- 国内最大級の動画生成AI「NoLang」、自治体・官公庁向けに本格, https://news.nicovideo.jp/watch/nw18776375?news_ref=watch_60_nw5686786
- 【公式】ReadSpeaker(リードスピーカー) | AI音声合成ソフト,読み上げツール, https://readspeaker.jp/
- 動画生成AI「NoLang」、メディア・出版業界向けにソリューションを本格展開。サイト滞在時間延長でSEO評価を高め、記事からのCV率向上で売上拡大へ – PR TIMES, https://prtimes.jp/main/html/rd/p/000000077.000129953.html